1. Download the eclipse source from CVS
You have to Checkout project from CVS Repository, refer to http://wiki.eclipse.org/CVS_Howto
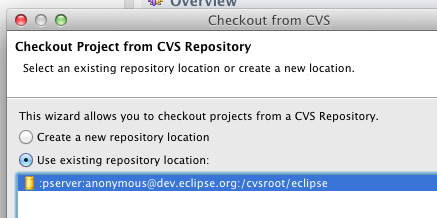
Based on your workspace, you’ll have e4 directory that has many eclipse projects.

It’ll start building when you setup automatic build.

2. Removing “API Baselines error”
After the automatic build, you may see a lot of “red !” and “red X” marks in some of the projects.
Refer to http://stackoverflow.com/questions/13650375/the-red-mark-after-the-build-in-eclipse. For your conveniences in debugging, you need to setup the filter. http://stackoverflow.com/a/13651021/260127
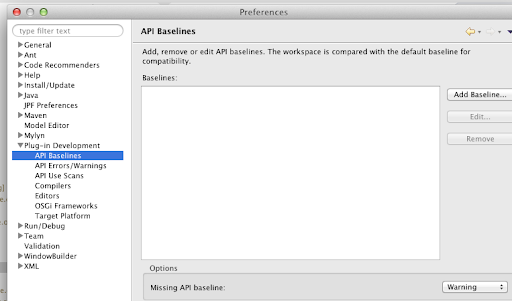
You’ll have “Adding API Baseline in eclipse” error.
http://stackoverflow.com/questions/13651144/adding-api-baseline-in-eclipse
You can remove all the errors by making “Missing API baseline” as warning.
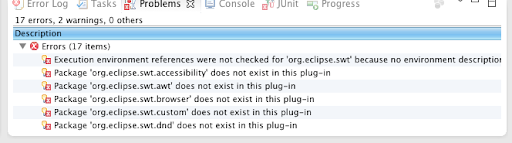
3. Removing “Build path specifies execution environment J2SE-1.4” error
You may see “Build path specifies execution environment J2SE-1.4.” error in Mac OS X, it’s because some of the projects use JDK1.4, but the setup in the Mac is wrong.

In eclipse Preference, you need to add Compatible JREs.

Check if you have Java SE correctly installed.

Then find all the projects with the “Build path specifies execution environment J2SE-1.4.” error.

Open the “Configure File Path”.
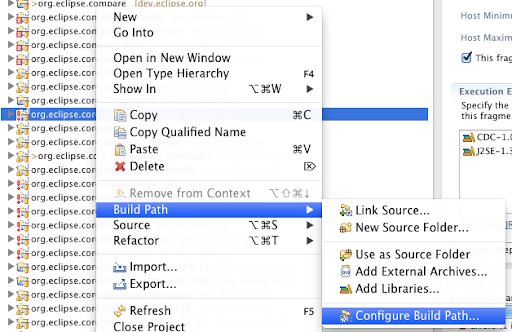
Replace the JRE System Library
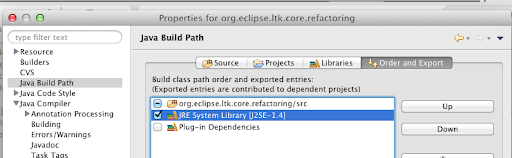
with the one with you just setup.
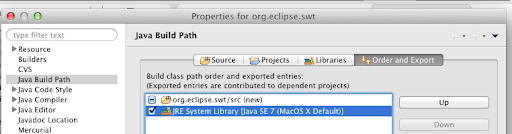
Install Execution Environment Descriptor


 Inside the file, we have all the directory information that points to the jar file and others.
Inside the file, we have all the directory information that points to the jar file and others.
 This is an example to get two summary files to execute the
This is an example to get two summary files to execute the 